



你是否需要刪除 Google搜索結果 、圖片?這篇文章提供五種方法讓你輕鬆移除
使用錯誤的方法不僅有時會導致頁面無法按預期從索引中刪除,而且還會對SEO產生負面影響 。
本文重點:
是否被編入索引的做法是使用在Google中搜索(例如site:Techeye-hk.com)。
這個方法很多人會用,但必須小心,因為它們不是正常的查詢,並且實際上不會告訴您頁面是否已經被Google 索引。它們可能會顯示Google已知的頁面,但這並不意味所有索引的頁面。
例如,site:domain 可以顯示重定向或規範化到另一個頁面的頁面。當您Search 某個網站時,Google可能會顯示該域中的頁面以及其他域的內容,標題和說明。以moz.com為例,該網站以前的網址是seomoz.org。導致訪問moz.com頁面的任何常規用戶查詢都將在SERP中顯示moz.com ,而site:seomoz.org將在搜索結果中顯示seomoz.org,如下所示。
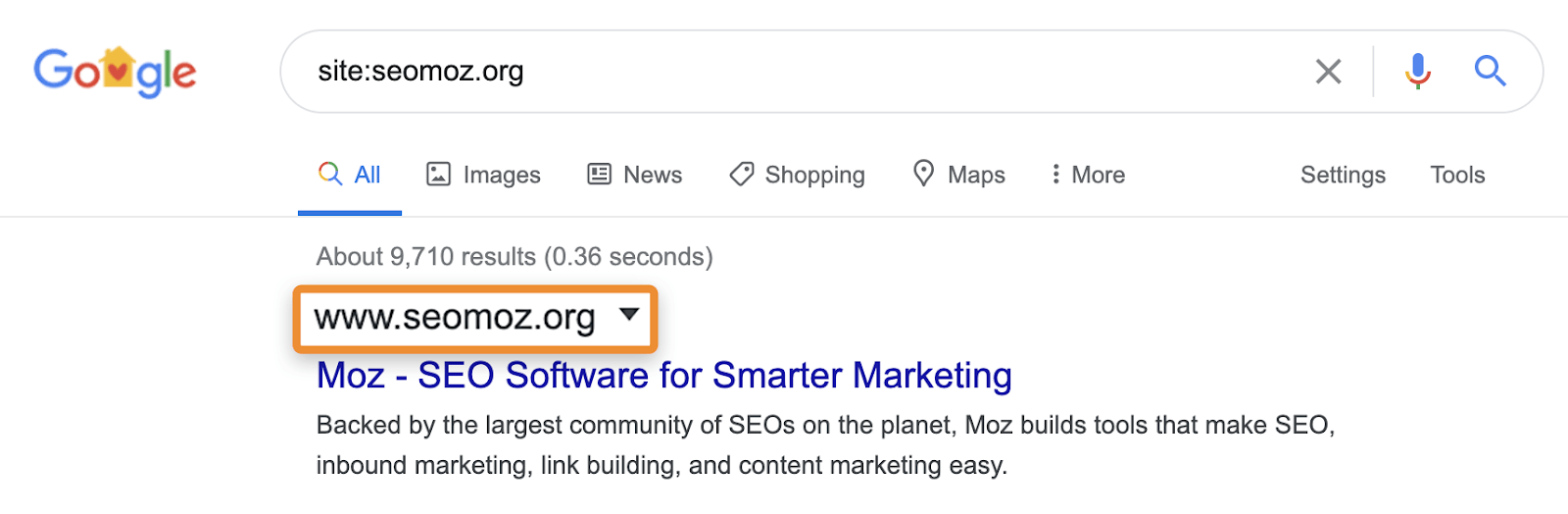
這是一個重要區別的原因是,它可能導致SEO犯一些錯誤,例如主動阻止或從舊域的索引中刪除URL,這會阻止諸如PageRank之類的信號合併。很多網站遷移的案例,大家認為他們在遷移過程中犯了一個錯誤,因為這些頁面仍顯示用於site:old-domain.com去做搜尋,。
檢查索引頁面的更好方法是使用 Google Search Console,或使用單個URL的URL Inspection Tool。這些工具會告訴您頁面是否已編入索引,並提供有關Google如何處理該頁面的其他信息。如果您無權訪問,只需在Google中搜索頁面的完整URL。
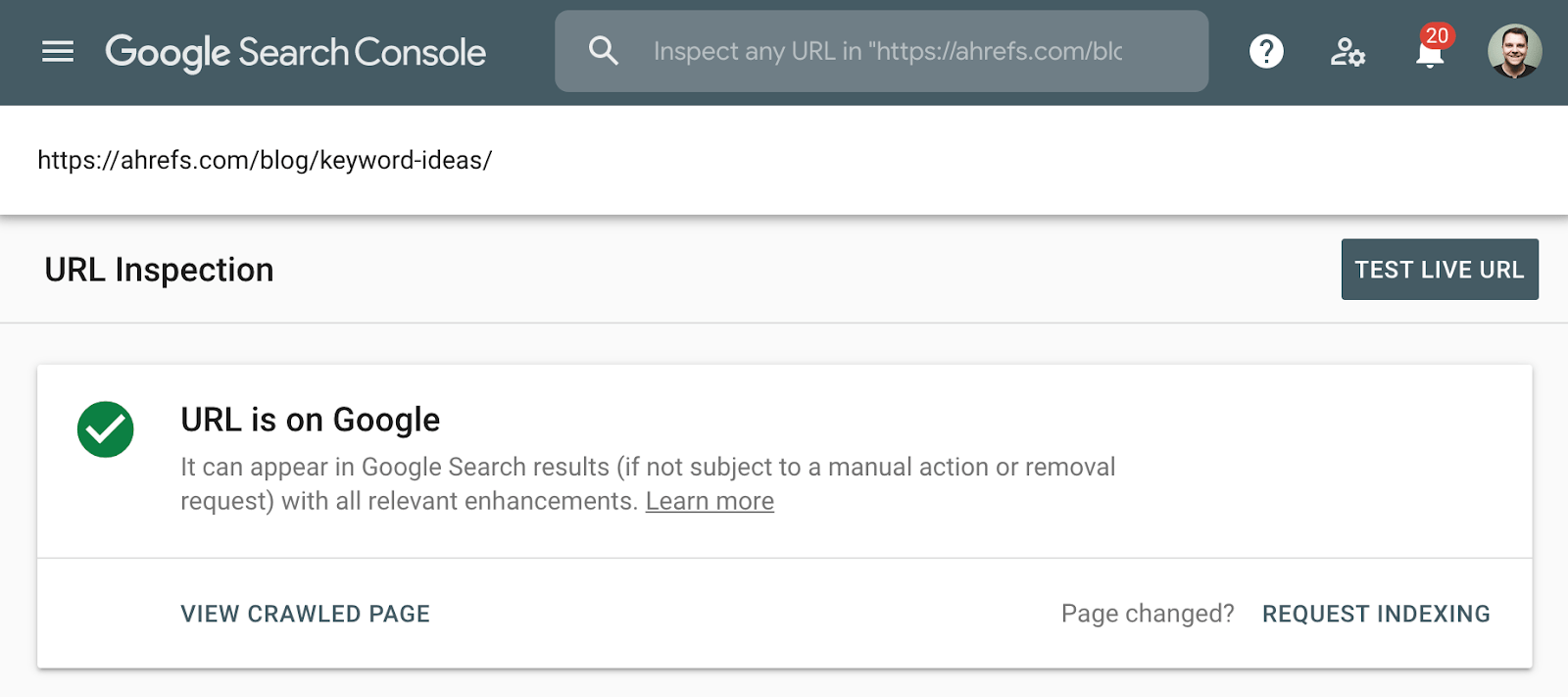
如果您刪除該頁面並提供404(未找到)或410(已消失)狀態代碼,則該頁面將在Google重新爬網後不久從索引中刪除。在將其刪除之前,該頁面可能仍會顯示在Google搜索結果中。即使頁面本身不再可用,頁面的緩存版本也可能暫時可用。
當您可能需要其他選項時:
noindex元漫遊器標籤 或x-robots標頭響應將告訴搜索引擎從索引中刪除頁面。meta robots標記適用於頁面,而x-robots響應適用於頁面和其他文件類型(例如PDF)。為了讓這些標籤可見,搜索引擎需要能夠對頁面進行爬網,因此請確保它們未在robots.txt中被阻止。另外,請注意,從索引中刪除頁面可能會阻止鏈接和其他信號的合併。
元機器人noindex的示例:
<meta name =“ robots” content =“ noindex”>
標頭響應中的x-robots noindex標記示例:
HTTP / 1.1 200 OK X-Robots-Tag:noindex
當您可能需要其他選項時:
如果您希望某些用戶可以訪問該頁面,但搜索引擎不能訪問該頁面,那麼您可能想要的是以下三個選項之一:
這種類型的設置最適合內部網絡,僅會員內容或暫存,測試或開發站點之類的事情。它允許一組用戶訪問頁面,但是搜索引擎將無法訪問他們,也不會為頁面建立索引。
當您可能需要其他選項時:
它的工作方式是暫時隱藏內容,有時候用於網站維護或其他目的,這個工具會令Google仍會看到並抓取此內容,但頁面不會顯示給用戶。這種暫時性影響在Google中持續六個月,而Bing有一個類似的工具可以持續三個月。在最極端的情況下,應使用這些工具來處理安全問題,數據洩漏,個人身份信息(PII)等問題。對於Google,請使用刪除工具 ;對於Bing,請參閱如何阻止URL。
您仍然需要應用另一種方法以及使用刪除工具將網站變成無Google索引或刪除頁面,或者如果用戶仍然看到你網站的連結,則可以阻止他們訪問內容。這只是為您提供了一種更快的隱藏頁面的方法,而刪除操作尚需時日。該請求最多可能需要一天的時間來處理。
當您有一個頁面的多個版本並且想要合併信號(例如到單個版本的鏈接)時,您要做的是某種形式的規範化。這主要是為了 在將頁面的多個版本合併到單個索引URL時防止重複的內容。
您有幾個規範化選項:
如果您有多個要從Google索引中刪除的頁面,則應相應地對它們進行優先排序。
最高優先級:這些頁面通常與安全相關或與機密數據相關。這包括包含個人數據(PII),客戶數據或專有信息的內容。
中優先級:通常涉及針對特定用戶組的內容。公司Intranet或員工門戶網站,僅供會員使用的內容以及暫存,測試或開發環境。
低優先級:這些頁面通常涉及 某種重複內容。這樣的一些示例將包括從多個URL提供的頁面,帶有參數的URL,並且可能還包括暫存,測試或開發環境。
幾種清除操作不正確的方法,以及每種情況下會發生什麼情況。
Google曾經在robots.txt中非正式地支持noindex,但它從來都不是官方標準,他們現在已經正式取消了對support的支持。許多這樣做的網站這樣做是不正確的行為,並損害了自己的Seo。
搜尋與建立索引不同。即使Google被禁止抓取頁面,即使頁面有任何內部或外部鏈接,他們仍然可以將其編入索引。Google不會知道頁面上的內容,因為他們不會對其進行爬網,但是他們知道頁面的存在,甚至會根據諸如 頁面鏈接的錨文本之類的信號編寫標題以顯示在搜索結果中。
通常對於noindex會感到困惑,有些人會在頁面使用它,期望頁面不會被索引。Nofollow 是一個提示,雖然它最初使頁面上的鏈接以及具有nofollow屬性的單個鏈接停止了爬網,但情況不再如此。Google現在可以根據需要抓取這些鏈接。Nofollow還用於單個鏈接上,以試圖阻止Google爬網到特定頁面並進行PageRank排名。同樣,由於nofollow是一個提示,因此這不再起作用。過去,如果頁面上有另一個鏈接,則Google仍可以從此替代爬網路徑中找到。
由於不遵循頁面上的所有鏈接幾乎沒有意義,因此結果數應為零或接近零。如果有匹配的結果,我敦促您檢查是否意外添加了nofollow指令代替noindex,並在需要時選擇一種更合適的刪除方法。
您也可以在鏈接資源管理器中使用此過濾器查找標記為nofollow的單個鏈接。
這些信號是矛盾的。Noindex表示要從索引中刪除該頁面,而規範表示另一個頁面是應建立索引的版本。這實際上可能對合併有效,因為Google通常會選擇忽略noindex,而是使用規範作為主要信號。但是,這不是絕對行為。其中涉及一種算法,並且存在noindex標籤可能是信號計數的風險。如果是這種情況,那麼頁面將無法正確合併。
請注意,您可以在“站點審核”的“頁面資源管理器”中使用這組過濾器找到帶有非自引用規範的無索引頁面:
通常有兩種方法:
無論哪種方式,都將阻止最終Google繼續爬網。
如果您擁有在其他網站上使用的內容,則可以根據《數字千年版權法案》(DMCA)提出索賠。您可以使用Google的版權刪除工具 進行DMCA刪除,該刪除要求刪除所有受版權保護的材料。
要從Google刪除圖片,最簡單的方法是使用robots.txt。正如我們前面提到的,雖然從robots.txt中刪除了刪除頁面的非官方支持,但簡單地禁止抓取圖像是刪除圖像的正確方法。
對於單個圖像:
用戶代理:Googlebot-Image 禁止:/images/dogs.jpg
對於所有圖像:
用戶代理:Googlebot-Image 不允許: /





